Building Modern AI-Enabled Infrastructure for Pharma: A Conversation with Anthony Bradley from Dalton
by Corin Wagen · Mar 17th, 2026
It's become almost banal to say that AI will accelerate drug discovery: there are dozens of high-profile companies currently building AI-powered drug-discovery platforms, dozens more working to provide AI-enabled tools to other therapeutics companies, and every major pharmaceutical company has teams working to employ AI internally.
One startup building in this space is Dalton, which recently announced a £4 million seed round to build "an adaptive intelligent system that evolves with your science, integrates seamlessly into your workflows, and puts lasting capability in your hands." In an increasingly crowded landscape, Dalton stands out: the founding team has extensive real-world pharma experience, making their AI optimism more credible, and their public statements emphasize deep workflow integration instead of the performance of any particular scientific model.
I reached out to Anthony Bradley, CSO and Dalton co-founder, to understand how they're thinking about providing value to pharma, what they hope to accomplish in this space, and what advice they'd give to other software companies hoping to make a difference in early-stage drug discovery.

Anthony Bradley, co-founder of Dalton
Corin Wagen: Anthony, you're a co-founder of Dalton, which is building an "intelligence backbone for drug discovery." Can you talk a little bit more about what you guys do?
Anthony Bradley: Yeah, for sure. We're trying to turn all of the amazing advances in computation and artificial intelligence over the past decades into meaningful impact in the drug-discovery industry.
What we've learned over the past couple of decades is: you need super scalable, super robust, super fault-tolerant engineering. You need amazing scientists who can take the advances that are happening, understand all of the available literature, and turn them into tools that sit on that platform. And then the third bit you need is advanced digital twins and a mechanism for translating those predictions into meaningful impact. Some people understand one of those components, but very few people understand all of that and how to then translate that into impact.
Corin: You have worked across a lot of different areas in drug discovery: you've been in academia, you've done more project support–type roles, you've done tool building, you've done infrastructure and file formats. How has all that informed how you think about Dalton and where you see the big opportunities and needs in this stack?
Anthony: I've done a whole bunch of different things. One of the things—a massive opportunity that I got during my PhD—was to actually spend about half of my PhD in a wet lab and sit at two interfaces: between academic research and actually applying it, and then also wet-lab and dry-lab work. That's where the profound shift is happening at the moment in the industry, at those two interfaces. I got an amazing opportunity to work on high-throughput fragment screening using X-ray crystallography and deeply understand how experimental structural biology works, how to scale experiments, how to automate experiments, and then how to build computational tools that sit on top of those capabilities.
And then again at Exscientia I got an amazing opportunity to work as part of project teams to understand how you know you actually deliver small-molecule drugs using AI: and it's not "you sit in front of a computer and you press a button and the computer gives you the answer." You work as part of amazing interdisciplinary teams who bring decades of their own expertise and experience, and then you use the algorithms to solve individual problems within all of that.
And I think two things stood out for me. There are definitely amazing opportunities to improve how drug discovery runs and operates—because as with any industry there are big inefficiencies or big ways that you could change things using computation—but that those solutions are never very simple. Everyone looking in on the outside thinks "you just need to apply AI and suddenly you magically solve this drug-discovery problem." The story is extremely complex, but that doesn't mean that you can't algorithmically improve things.
We were part of the groups of people showing that in Exscientia that you can reduce timelines, you can improve efficiency, you can deliver compounds that make it into clinical studies using artificial intelligence. A bunch of groups are compounding that—Insilico Medicine, for example—and showing you can demonstrate a whole bunch of clinical candidates, you can improve timelines, and you can deliver things more efficiently as part of these holistic systems. But I think in reality, when you think about it, we're really very much at the beginning of that journey.
And the other really cool thing that I've seen is that when I started in this area, no one really cared about it at all. And this wasn't that long ago; I'm not quite that old. 10–15 years ago, there was very little interest in this space. It was relatively niche. It felt really stagnant. It felt like an area where things hadn't really moved all that much for a while and then over the past 5 or 10 years it's become part of dinner-table conversation. My parents know about AlphaFold, and everybody knows about protein–ligand docking, which is both extremely strange but also really exciting because obviously I think this is an extremely important problem.
I remember thinking, 10–15 years ago, everybody cared about social media and Snapchat and Facebook and building applications that didn't really deliver that much societal value and now what's really cool is those same companies—like TikTok—are delivering protein–ligand docking tools that are world-leading and cutting-edge and amazingly powerful and that's actually a really cool societal transformation.
Corin: Popular wisdom, at least among VCs, is that it's basically impossible to build a software company that sells to scientists. What do you think these investors misunderstand? Why doesn't top-20 pharma just build Dalton themselves internally?
Anthony: So there's a bunch of different questions and it depends where you sit within the different segments. It depends on the pharma company; different pharma companies have different views on this, but a lot of them are not at all interested in becoming a software company themselves. They have their own core strengths, and if their core strength isn't software development, they outsource that because you should focus on your core strengths.
And then if you look actually at where a lot of drug discovery is being done, particularly early-stage drug discovery, it isn't being done in big pharma. It's being done within the thousands of biotechs that exist across the world, and for those companies it's just not possible for them to build their own software platform. They need to build their own target portfolio. They need to then discover drugs within that. If every single one of them is then tasked to build their own software platform, that makes absolutely no sense at all.
Finally, CROs are the third segment. Again, at least half of all wet-lab experimentation is done within CROs and again it's definitively not their specialization to build innovative software capabilities. That's not what they've focused on so far and so again it makes sense for them to outsource.
To answer your first question, I think it is clear that people's view on what pharma will and won't buy in terms of software is now changing. We're seeing new deals shaping the industry where pharma are investing big in multi-year software deals that look a lot more like what you would expect to see within the industry. And again I think that some of the pessimism is being driven by actually just a lack of maturity of the software platforms.
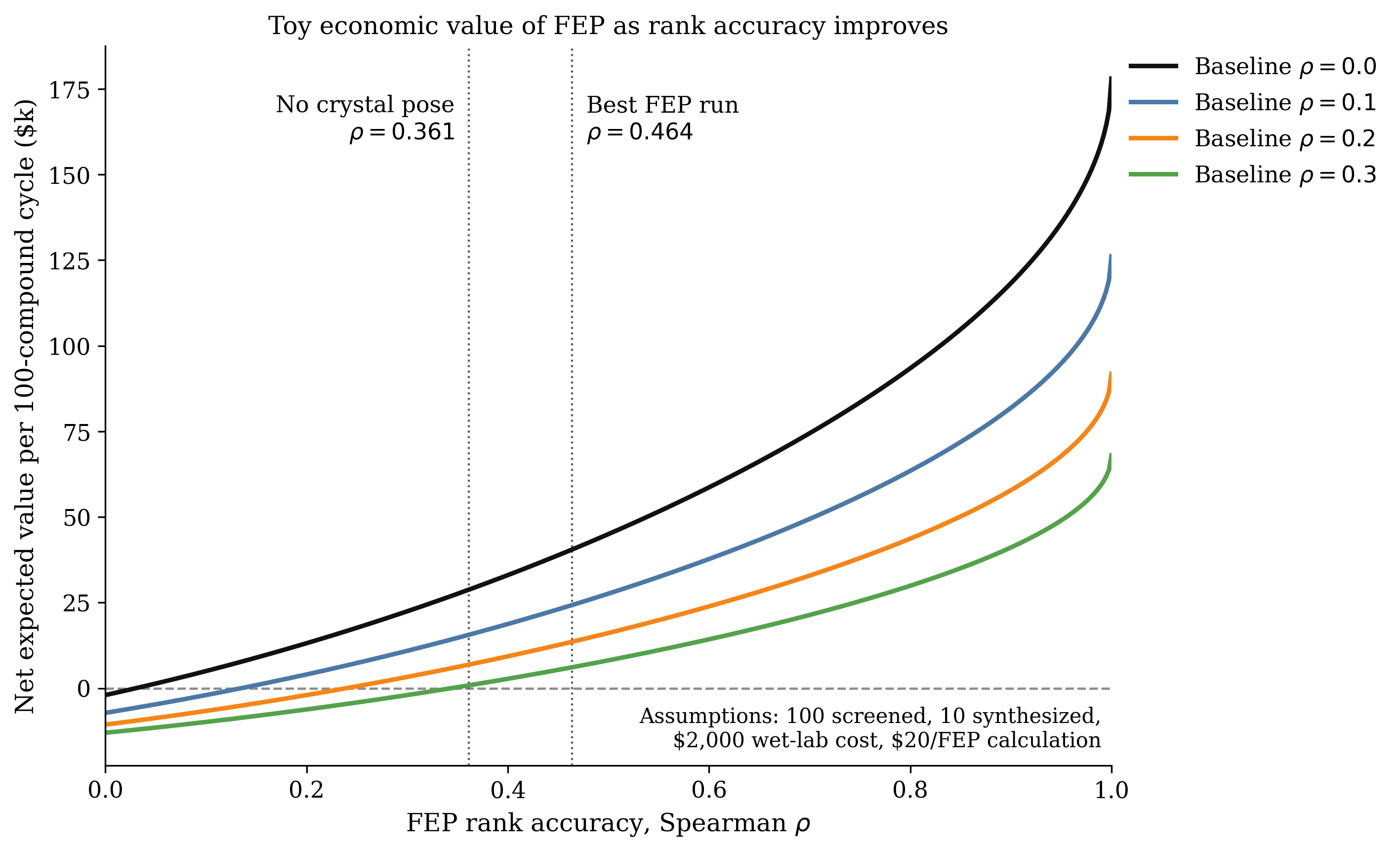
There's a relatively small number of players within that space who have been building things that are actually impactful for a pretty short period of time. Schrödinger's FEP, which is not that old, is probably one of the watershed moments of people saying "we can actually predict things that are really useful" and everyone mostly agreeing on that. Obviously then everyone says this shows the upper limit of what you are able to sell within software. I don't think that makes any sense at all. What they're showing is that it is possible to create a really great software business if you have this capability, and as people build more and more sophisticated capabilities they will be able to sell more and more into the industry. And you'll see, as you see in every other industry in the world, loads of different ways of monetizing software effectively.
Corin: And I guess this goes back to your original point about actually delivering value. Predictive binding affinity clearly delivers value, but that's not the only place you could deliver value. That's the first step and the step that's succeeded so far. But it doesn't make sense to see that as an upper limit.
Anthony: Yeah. And the reality is that those companies don't typically sell the value, they sell the capability. So if you buy a piece of software, you buy a docking algorithm that has a set of benchmarks to say that it's good. But what you're not buying off that company is "I'm going to reduce your inefficiency by 10% or 5%." You're not buying that efficiency improvement or a clear ability to deliver on projects. And as people get closer and closer to being able to sell the value, essentially you're moving money from a company's wet-lab budget onto their dry-lab budget and you can demonstrate that clear value. That will also change the industry for sure.
Corin: You made an interesting point in your previous response, about the fragmentation of early-stage drug discovery. Essentially, more and more has moved out of these pharma monoliths and into the sea of smaller biotech companies. Does that imply that it's going to be a lot easier in the future to build an ecosystem vendor, because the number of customers is much larger and there's just essentially much higher returns to scale?
Anthony: I think it does. I think it also creates some complexity, and it depends how the remaining components of the market shape up.
The first area where we've already seen that you can sell really scalably is companies like Benchling and that kind of data-management software. They've demonstrated that you can create super scalable sales into a biotech industry, which actually then helps everybody else, because if you have that kind of data framework somewhat standardized with really nice APIs and the ability to integrate with them, then that means that other people can build on top of that nicely.
I think the component that probably has yet to be solved—and we're hoping to make a dent into—is that each of those individual companies has relatively bespoke scientific needs related to the modality that they're going after or the biological angle they want to go after. And I think that's the complexity that will enable multiple companies to be able to be working in that space, because there are a lot of different computational challenges to go after. But the people who can solve as many of those problems at once or within their own platform are the people who will do the best, and we're hoping to do that.
Corin: That makes sense. Staying on the organizational theme, do you think that the fundamental organization of pharma will need to change moving forward, or do you expect that top-20 pharma will never change? You know, it's been around for a century and a half and it will stay the same for another century and a half.
Anthony: It's a good question. I personally think the shift away from doing your own internal drug discovery has a massive logic to it. Companies tend to specialize in the things that they're particularly good at. And the thing that pharma are particularly good at is taking molecules, developing them, marketing them, selling them, and picking disease areas to work in. Those are the things that they want to specialize in.
Corin: Yeah, it's interesting to think about a world in which there's a glut of competent candidates for any given target, and the rate-limiting step becomes pharma acquisition.
Anthony: Yeah. I read recently something that's talking about how any efficiency improvement immediately gets lost into improving the quality of the target–product profile. So as you get more efficient, you just make better drugs. And both of those things can be sort of true at the same time. But yeah, I think you'll have a relative glut in terms of the sophistication of those modalities as well as the number of those different compounds.
Corin: Which is great! We want efficiency to get lost into a better target–product profile. I mean, Mark Murcko had that recent piece about binding affinity which makes a very similar point: we want to have compounds that can potentially have great binding affinity so then we can sacrifice that on the altar of ADME or toxicity or whatever. That's a favorable position to be in for the field.
Anthony: It is. I think the only concern is that the drivers for biotechs can be relatively short-term, because for each one of them, the thing that makes them more innovative can also lead to lower quality compounds being pushed as far forward as they possibly can be. I think that's something that the industry should be cognizant of.
Corin: Can you explain that point in slightly more detail?
Anthony: An individual biotech will have a defined runway that they have, in terms of money, and that leads to improved efficiency and improved delivery because you have to just say "I'm going to deliver something in 12 months, 18 months, come hell or high water." It also pushes you to move things into phase 1 and phase 2 clinical trials—because that's where your value inflection points come and that's where your ability to raise money comes—at earlier stages than you possibly would do within big pharma.
Now, that can have benefits because it means that you move things forward more quickly, but it also obviously has risks. It has the massive risk of potentially putting lower quality molecules into clinical trials. It's just an incentive structure that exists within biotech.
And the corollary is that the major driver of small-molecule drug-discovery costs is obviously clinical failures. And so reducing the quality of the compounds, increasing the risk of clinical failures by pushing things forward earlier than they needed to do overall collectively drives inefficiency.
Corin: There's an incentive mismatch here. So, if I'm a biotech, I want to get my phase 1 data: I just want to get a molecule that's good enough, get it into clinical trials and then hopefully sell the asset to someone else and then they're left at the end of the day holding the bag on whether phase 3 works or not. In an ideal world, everyone's incentives would be perfectly aligned, but in actuality it's maybe not in the biotech's interests to spend the extra 6 months making the best possible molecule.
Anthony: Yes, exactly.
Corin: How has your love of Shoe Dog and Phil Knight impacted Dalton?
Anthony: I think it's a really nice book. One of the things I liked about it was that it felt like an honest representation of what it's like running a small company or a startup as it moves forward. Everything both feels amazing and also inherently extremely precarious, even though you know the ending is that this company became this enormous monolith, Nike.
Also I think what I loved was his motivation for building Nike. It was never money. It was never about him becoming personally wealthy. It was him building the kind of shoes that he wished he got to wear and that he thinks that everybody should wear and it was all built around his love and desire for the product. And I think that's what I love about running and building Dalton: it's not for any of us about individual wealth. It's about building the product that we think that the industry needs in order to develop better drugs.
And that is, I've learned, the only way to get myself up in the morning is to be building something that I really believe in. That infectious enthusiasm for shoes—which I don't really care much about—that ran through the book and that felt very real to me.
Corin: Do you have a version of the "Nike principles" for Dalton?
Anthony: No, I think we're a bit too British for that kind of thing.
Corin: You're not on offense all the time.
Anthony: Collectively, we know each other pretty well and we have a pretty shared understanding. What I love is that every day, when we come into the office, you can kind of see our collective personalities in the people who are there and the way that they interact with each other: friendly, but also there's constant discussion going on about a mixture of different scientific topics and everybody's just really motivated behind the mission.
Corin: In 2023, you said in an interview:
Within the current decade, all new drugs will be designed by AI. To be clear, this won't mean AI replacing humans, but it will mean companies using AI will win out.
You said that when you were at Exscientia, which obviously was very early to the AI drug discovery world. How would you say your perspective on AI drug discovery has changed over the past three years? AI scientists and LLMs are everywhere now, and your co-founder Adrian has written about agentic AI and the "third wave" of drug-discovery platforms. What would you say you've learned personally or changed your mind about?
Anthony: Yeah, that's a really good question. I think that that statement is quite funny. It sounds so not even vaguely controversial. So, it's so banal, benign, and uncontroversial now, right? But I feel like at that time it would have sounded a little more controversial than it currently does, which is really weird.
Corin: I agree!
Anthony: So the space has moved ridiculously fast, of course. We're at a really exciting point where, if we're really honest, none of us really know how this is going to land. We can see all of these different opportunities, and we can see capabilities just getting better and better on individual benchmarks, and we can see the potential power of these agentic systems. But what we're only beginning to show is how you can reduce them to practice on actually useful problems that aren't toys and aren't heavily fine-tuned for your particular example.
So I think what would have changed is what is now possible is very very different from what was possible 3 years ago. What that probably felt more like was "evolutionary capabilities get a little bit better over time and then you begin to integrate them a little bit more into the process." It has completely changed. Our ability to integrate with processes and then completely redefine processes because of those individual capabilities has totally changed.
And that's the actual opportunity for Dalton and for other companies to help the industry redefine those processes, because the other thing I think I've learned is that it won't happen within companies all that easily. You need an external stimulus of either a new company doing it completely differently or another company coming in and helping you to do it completely differently. So I think the process that you could run now is transformationally different.
As an example, you can trivially go through years and years of written experimental notes and turn that into structured data. Google released that yesterday: a completely open-source ability to do really complicated text extraction. Those capabilities are commoditized now, to some extent, whereas that used to be like 5–10 years worth of work of really great scientists to be able to build those capabilities. That just unlocks things that previously would have been impossible. You go into massive legacy organizations where dealing with any data that's older than a year or two may have been completely impossible.
Equally, what we can create as an interface is different. We were often building a platform in Exscientia that was aimed at computationally literate people, because it was not possible to create a platform that could be solely used by someone who doesn't understand computation. Whereas more and more… I don't mean that we won't have computational scientists, but you can create platforms that don't need any computational expertise at all.
We have people who can't code who are writing front-end components because they're capable of doing that and they know what they need to be able to do. And that just wasn't possible at all. And that means that you can have people who can't use quantum mechanical software—and you've already seen this—who can do quite complicated things without any computational understanding at all but just with deep domain knowledge.
So I think it is extremely heartening. I think there's also a massive risk of, as we often do in drug discovery, creating quite a lot of noise that doesn't actually improve timelines. As with anything, you can create something that you can spend time using that doesn't necessarily make you more effective; it can just take up more of your time. I think we need to be laser-focused on what's actually useful for people to be doing more of: is it actually useful for a medicinal chemist to spend their time doing quantum mechanical calculations that they couldn't previously do? How do we make sure that we're actually delivering impact?
Corin: One of the first lessons I learned when I moved out of the lab and started doing computations was "wow, you can waste a lot of time doing work in the computer that doesn't actually impact the real world at all." As the technical barrier of accessing computation goes to zero—if you can set up your quantum mechanics or your MD or your FEP just by clicking around—figuring out how to get the necessary domain knowledge and unify the disparate cultures is one of the big social tasks for the field. Maybe AI will help with that too. I don't know.
Anthony: Yes. I think it can, but as long as its own incentive structures are driven by the right things. One of the fears at the moment is that the major driver for all general-purpose language models is usage rather than impact, right? And so language models are really polite and they're a little sycophantic and they want to make you feel really smart, and that's because they want you to keep on using them.
Whereas actually if they just said "no, that's a really stupid question Anthony, I don't really know why you would even bother asking that," you would obviously stop using them. And I think as you create enterprise systems it's about driving that balance between usability and usefulness, and if you don't do that, then no one will bother paying for them. But if you don't make it usable, then no one's going to bother using them.
Corin: It's an interesting question too for companies like ours: how do you align your company's incentives towards being useful? Because like it or not, we're all victims of our own incentives.
Anthony: Right. Exactly.
Corin: Anything else you want our readers to know about Dalton, or anything we should be keeping our eyes out for over the next year or 18 months?
Anthony: It's a super exciting time for us. We're up to 25 people now at King's Cross and we're building out a really very cool platform. So it sits across small molecules and antibodies with a real focus on demonstrable impact, demonstrable efficiency improvement, or demonstrable ability to do something you couldn't previously do.